Wie immer am Anfang des Berichts kurz der Hinweis, dass alle Vorträge, Quelltexte, usw. - soweit
vorhanden bzw. mir bekannt - auf der Vortrags-Übersichts-Seite
verlinkt sind.
33 C++ Interessierte hatten den Weg raus in die Pascalstraße zu NI gefunden, um am C++ User-Treffen Aachen im Mai 2017 teilzunehmen. Für alle hat sich das Kommen gelohnt, denn es gab auch diesmal wieder vier richtig gute und vielfältige Vorträge zu hören.

Foto 01: C++ User-Treffen Aachen 11.5.2017
NI versorgte uns wieder nicht nur mit einem schönen Raum, sondern auch mit erfrischenden Getränken und schmackhaften Speisen - vielen Dank von hieraus an NI für die super Bewirtung.

Foto 02: C++ User-Treffen Aachen 11.5.2017

Foto 03: C++ User-Treffen Aachen 11.5.2017
Wie immer startete der Abend mit einer kurzen Einführung von mir und einem Ausblick auf die Vorträge des nächsten Treffens im Juli. Diesmal war ich aber nicht nach wenigen Minuten fertig, denn ich hatte ein weiteres Thema im Gepäck: verschiedene regelmäßige Teilnehmer des C++ Treffens in Aachen hatten mich angesprochen ob wir uns nicht häufiger treffen könnten. Zum einen - wenn man bei einem Treffen mal nicht kann, würden 4 Monate ohne C++ vergehen - und das hält kein Informatiker wirklich aus. Außerdem gibt es eine große Zahl an zugesagten Vorträgen, so dass meine aktuelle Planung bis in den Herbst 2018 geht. Genug Vorträge scheinen also da zu sein - und man könnte ja auch einen kleinen Vortrag weniger an den Abenden planen um mehr Freiraum für Diskussionen zu schaffen, wonach auch gefragt wurde.

Foto 04: Detlef Wilkening bei der obligatorischen Einleitung des C++ User-Treffens
Zwischenstand der Diskussion ist, das wir auf einen monatlichen Rhythmus mit Sommer- als auch Winter-Pause wechseln wollen. Im Sommer betrifft dies dann Juli und/oder August - im Winter den Dezember. Wir würden dann bei 10 Terminen im Jahr landen. Zur Zeit stehe ich in Diskussion mit den Firmen, die uns die Räume zur Verfügung stellen, ob sie mehr Termine im Jahr sponsoren würden. Der nächste Termin wird also erstmal weiter in zwei Monaten sein, also am Do. 13.7.2017. Dann werde ich berichten, wie es weitergeht.
Der erste fachliche C++ Vortrag war dann von Michael Becker mit dem Thema "Type Erasures". Type Erasure meint, dass man z.B. eine Funktion (eine normale Funktion, kein Funktions-Template) schreiben kann, die alle Typen annimmt die bestimmte Fähigkeiten haben. Oder einen Container, der eben alle Typen aufnimmt der bestimmte Methoden hat. Der echte Typ spielt hierbei also keine Rolle mehr, sondern das was man mit den Objekten machen kann. Es ist ein bisschen wie "Duck-Typing" zur Compile-Zeit.

Foto 05: Michael Becker mit "Type Erasures"
Michael motivierte erstmal, welche Probleme man mit Type-Erasures lösen kann - und zeigte dann verschiedene Lösungs-Ansätze auf C Ebene bzw. auf einfacher C++ Ebene, um die Ideen zu verdeutlichen - die aber alle einige Nachteile hatten. Dann wechselte er zu einer echten C++ Lösung, die ohne all diese Nachteile auskam und baute einen Typ "drawable", der alle Typen die eine "draw" Funktion haben, aufnehmen kann.

Foto 06: C++ User-Treffen Aachen 11.5.2017
Sicher sind Type Erasures nicht die Lösung für alle Probleme der Welt - ganz im Gegenteil wird man sie nicht jeden Tag benötigen - aber wenn man ein entsprechendes Problem hat ist man froh in C++ wieder mal eine einfache und mächtige Lösung implementieren zu können. Michael konnte dies erfolgreich motivieren und zeigen - ein sehr spannender Vortrag.
Den nächsten Vortrag hielt dann Michael Wichary, der über "Auto-Erkennung mit der DLib" referierte. Michael startete direkt mit einem schönen Eye-Catcher in den Vortrag: ein Foto mit einem Auto. Und zeigte dann das sein Programm dieses Auto im Bild erkennen kann und mit einem Rahmen umrandet. Damit war klar, was "Auto-Erkennung" meint: das Erkennen von Autos in Bildern.

Foto 07: Michael Wichary mit "Auto-Erkennung mit der DLib"
Michael hatte dies mit mehreren Kommilitonen im Rahmen eines SWE Projekts im Bachelor-Studiengang umsetzen müssen. Der Rahmen dieses Projektes gab vor, dass die Erkennung nicht selber umgesetzt werden konnte, sondern auf eine fertige Lösung zurückgegriffen werden musste. Michael und seine Mitstreiter hatten hierfür die C++ Bibliothek "DLib" genommen - auch aus anderen Gründen. Die DLib bietet neben vielen anderen Featuren auch die Erkennung von Objekten an.
Nachdem das Thema nun klar war, erklärte Michael zuerst, wie die DLib intern arbeitet. Und er referierte über Gradienten- und Farb-Normalisierung, über HOGs und Stütz-Vektor-Maschinen. Stück für Stück stellte Michael die Mechanismen vor, die die DLib intern benutzt, und erklärte sie anhand von hilfreichen Beispielen. Außerdem zeigte er, wie man die DLib trainiert und den entstandenen Detektor dann in sein Programm einbindet.

Foto 08: Michael Wichary mit "Auto-Erkennung mit der DLib"
Danach zeigte er die Grenzen der Objekt-Erkennung mit der DLib auf, die sich zum Teil nach dem Verstehen der internen Arbeitsweise quasi von allein ergaben - Michael hatte viele Beispiele vorbereitet, bei denen die Autos zum Teil erkannt wurden und zum Teil nicht. Unterm Strich ein sehr interessanter Vortrag, selbst wenn nur wenig C++ darin vorkam - aber eben ein Thema, das zur Zeit sehr angesagt ist.
Nach diesen zwei längeren Vorträgen war erstmal eine Pause notwendig - die Teilnehmer nutzten die Gelegenheit, widmeten sich den Getränken und Speisen, und diskutierten das Gehörte.

Foto 09: C++ User-Treffen Aachen 11.5.2017

Foto 10: C++ User-Treffen Aachen 11.5.2017

Foto 11: C++ User-Treffen Aachen 11.5.2017
Nach der Pause ging es weiter mit einem kleinen Vortrag von Daniel Evers über "Custom Python interpreter for enhanced secrecy". Daniel stellte sich extra einen Wecker, damit er auf keinen Fall länger als 15 Minuten brauchen würde - bedingt durch viele Zwischenfragen und Diskussionen musste er diesen Zeit-Rahmen dann aber auch vollständig ausschöpfen.

Foto 12: Daniel Evers mit "Custom Python interpreter for enhanced secrecy"
Daniels Vortrag ging um folgendes Thema: da hat man nun ein schönes Python Skript zur Automatisierung von Abläufen, und in diesem Skript könnten nun z.B. Datenbank-Passwörter auftauchen. Wie sichert man diese gegen unberechtigten Zugriff. Daniel hatte eine ganze Palette von Ideen in petto - von C++ Binaries die die Connection aufbauen und das Passwort intern verwalten bis hin zur Ausführung von Zip-Dateien mit Python. Er stellte aber auch immer klar, dass eine vollständige Sicherheit prinzipbedingt nicht möglich ist, sondern alles nur immer stärkere Ausprägungen von Obfuscating darstellen. Aber irgendwann ist der Aufwand, die Passwörter zu extrahieren halt so hoch, dass andere Angriffsziele einfacher und erfolg-versprechender sind. Und dann ist das Skript eben nicht mehr der Schwachpunkt. Ein sehr interessanter und kurzweiliger Vortrag.
Zu guter Letzt hatten wir Besuch aus Köln. Die Gründer des C++ User-Treffens Köln Michael Wielpütz & Thorsten Wendt waren zu Besuch in Aachen und schwer beeindruckt von der excellenten Organisation und der Qualität der Vorträge. Aber sie trugen selber mit einem Vortrag über den "Einfluss von Memory-Barrieren auf Smart Pointer" mit zu der hohen Qualität bei.

Foto 13: Michael Wielpütz & Thorsten Wendt mit "Einfluss von Memory-Barrieren auf Smart-Pointer"
Michael und Thorsten begannen mit einer kurzen Einführung in Smart-Pointer. Dabei zeigten sie, dass man in einer Multi-Thread Umgebung den Ref-Counter der Shared-Pointer natürlich vor Race-Conditions schützen muss. Dies betrifft u.a. den Kopier-Konstruktor, beim der Ref-Counter ja verändert wird. Die interessante Frage war dann: in wie weit beeinflussen Memory-Barrieren die Performance von Shared-Poinern z.B. beim Kopieren.

Foto 14: Thorsten Wendt mit "Einfluss von Memory-Barrieren auf Smart-Pointer"
Um diese Frage zu beantworten, stiegen Michael & Thorsten tief in die Hardware hinab und zeigten was genau in einem Multi-Core Prozessor passieren kann, bzw. wie dieser die Cache-Kohärenz wahrt. Hierfür nutzen sie beispielhaft das MESI (Modified Exclusive Shared Invalid) Protokoll zur Wahrung der Cache-Kohärenz in speichergekoppelten Multiprozessorsystemen.
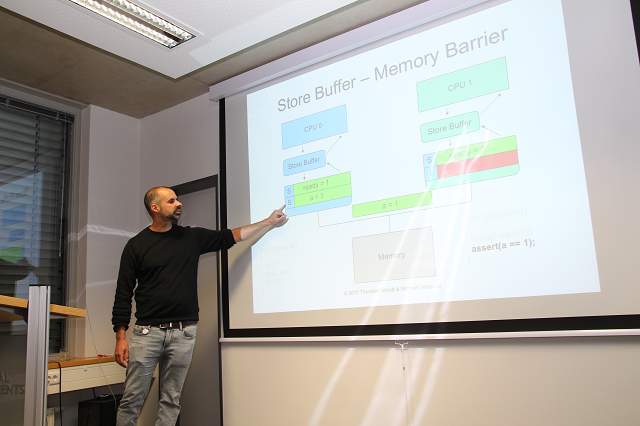
Foto 15: Michael Wielpütz mit "Einfluss von Memory-Barrieren auf Smart-Pointer"
Um die theoretischen Erkenntnisse abzusichern hatten sie dann ein Beispiel-Programm geschrieben, bei dem sie Shared-Pointer mit Kopien bzw. Const-Referenzen einsetzten - und verglichen die Performance in beiden Fällen. Nach den theoretischen Überlegungen nicht mehr verwunderlich, war die Const-Referenz Variante den Faktor 5 schneller. Auch Kopien von Shared-Pointern können also wesentliche Performance-Kosten verursachen. Auf der anderen Seite benötigt man das entsprechende Verhalten (es ist immer eine Referenz da und das Objekt wird nicht gelöscht) manchmal - dann muss man diesen Preis auch zahlen. Ansonsten sind natürlich Const-Referenzen der Kopie vorzuziehen - auch bei so einfachen Objekten wir Shared-Pointern.
Den nächsten Termin, weitere Berichte und andere Informationen zu den C++ User-Treffen in Aachen finden sich auf meiner "C++ User-Treffen in Aachen" Seite.