18.04.2012
Version: 1
Hinweis - dieser Artikel entspricht den Folien des Vortrags, den ich am 18.04.2012 auf dem 5-ten C++ Treffen in Düsseldorf gehalten habe.
Inhaltsverzeichnis
1. Einführung
1.1 Performance
- "There is no silver bullet for good performance"
- Gute Performance ist das Ergebnis harter Arbeit
-
Gute Performance kommt nicht von alleine
- Auch nicht in C++
- Und auch nicht in Java
-
Gute Performance ist das Ergebnis von:
- Ständiger Kontrolle
- Gutem Design
- Effiziente Algorithmen
- Angemessene Nutzung der Sprachmittel und Bibliotheken
- Unterstützung des Compilers und der Hardware
- Nutzung von Multi-Threading
-
Wir reden heute
- Primär über "Angemessene Nutzung der Sprachmittel"
- Der Rest muss auf ein anderes mal warten
-
Aber (meist) noch wichtiger als Performance ist:
-
Korrektheit (Fehlerfreiheit) des Programms
- Dies sollte immer der wichtigste Punkt sein!
- Wartbarkeit des Quelltextes
- Lesbarkeit des Quelltextes
- Erweiterbarkeit des Programms
-
Portabilität
- Portabilität ist manchmal sehr wichtig, aber manchmal auch unwichtig
-
Korrektheit (Fehlerfreiheit) des Programms
-
Performance steht manchmal im Gegensatz zu:
-
Anpaßbare Architektur, z.B.:
- Schichtenmodelle
- Dynamische Konfiguration
-
Speicherverbrauch, z.B.:
- Ergebnisse werden gecacht statt jedesmal neu berechnet
- Objekte werden für schnellen Zugriff strukturiert
- Elemente werden redundant gehalten
-
Portabilität
- Ausnutzen spezieller Größen
- Nutzung von Inline-Assembler
- Unterstützung der Hardware duch z.B. Vorlesen, Cache-Anpassungen
- Lesbarkeit der Quelltexte
- Zeitaufwand, d.h. Termintreue
-
Anpaßbare Architektur, z.B.:
-
Selbstverständlich sollte sein:
-
Klare Zielvorgaben, d.h.
-
Welche Workflows müssen in welcher Zeit abgearbeitet sein?
- Bei unbelastetem System bzw. bei belastetem System!
- Welche Operation darf max. wie lange dauern?
- Welche durchschnittliche Antwortzeit muss das System erreichen?
-
Welche Workflows müssen in welcher Zeit abgearbeitet sein?
- Ohne Zielvorgaben lohnt es sich nicht über Performance zu diskutieren
- Automatische-Tests, die diese Zielvorgaben checken
-
Performance Tests von Anfang an
- Sofort erkennen, wenn irgendwo Probleme entstehen
- Gegensteuern, solange die Problemstelle noch neu und übersichtlich ist
-
Klare Zielvorgaben, d.h.
- Hinterher ein in den Brunnen gefallenes Kind zu retten ist meist teuer
-
Wenn es ein Problem gibt:
- Sofort reagieren
-
Messen, was das Problem ist
- Es ist nicht immer das Netzwerk, die Datenbank, Windows oder Java
- Profiler nutzen
-
Nicht blind optimieren, sondern überlegen
- Welche Auswirkungen haben die Änderungen?
- Bringt die Stelle überhaupt was?
-
Kann das Problem übergeordnet besser gelöst werden?
- Z.B. nicht blind eine Funktion optimieren - vielleicht muss sie nur nicht immer aufgerufen werden
-
Wichtige Regeln:
-
Andere Ziele (Korrektheit, Lesbarkeit, Portabilität,...) gehen vor
- 1. Regel der Performance-Optimierung: "Mach es nicht"
- 2. Regel der Performance-Optimierung: "Mach es später"
-
Wenn es ein Performance-Problem gibt, erst versuchen auf grundsätzlicheren Ebenen zu lösen statt zu hacken:
- Architektur & Design
- Algorithmen
- Container
- Bessere Hardware
- Auf Ebene der Sprache immer die lesbare performante Lösung wählen
- Erst in letzter Konsequenz: hacken, Assembler, usw...
-
Andere Ziele (Korrektheit, Lesbarkeit, Portabilität,...) gehen vor
-
Die wichtigsten Mittel für Performance sind:
- Performante Algorithmen
- Performante Datenstrukturen
-
Multi-Threading
- Gerade im Zeichen von Hyper-Threading, Dual-Core, Quad-Core, usw.
-
Wichtige Hinweise bevor wir loslegen
-
Manche Optimierungen sind hardware abhängig
- D.h. bringen manchmal nix, manchmal viel, und manchmal gehen sie nach hinten los - je nach Hardware
-
Manche Optimierungen machen manche Compiler heute schon automatisch
- D.h. sie lassen sich nicht messen, und sind nur theoretisch begründbar
- Vielleicht sind sie aber trotzdem sinnvoll, da man möglicherweise mal einen Compiler erwischt, der es nicht selber macht... oder?
- Manche Optimierungen liegen im Konflikt mit Single- oder Multi-Threading
-
Manche Optimierungen sind hardware abhängig
- Lesen und Nutzen Sie also alles Folgende mit Vorsicht, Skepsis und Verstand
1.2 Hinweise zu den Tabellen mit den Messwerten
-
Wichtige Hinweise zu den Tabellen mit Messungen hinter den meisten Beispielen
-
Ich schreibe extra keine absoluten Zeit-Messwerte in die Tabellen
- Ich will hier keine Compiler und/oder Bibliotheken und/oder Plattformen vergleichen
- Die Zeiten sind zum Teil auf unterschiedlichen Computern gemessen, zum Teil sind es Mittelwerte aus Messungen auf mehreren Computern
- Also sind sie nicht absolut vergleichbar, und sie können bei Ihnen ganz (?) anders aussehen
-
Die Zahlen sind pro Compiler normiert auf die schnellste Variante - die bekommt die 1,0
- Also niemals, wirklich niemals die Zahlen der verschiedenen Compiler miteinander vergleichen
- Die 6,0 eines Compilers kann schneller sein als die 3,0 eines Anderen
- Der Code des Compilers mit kleineren Werten ist nicht unbedingt der schnellste Code
- Zur besseren Übersicht sind die 1,0 Zahlen (daher die schnellsten Ergebnisse) grün unterlegt.
-
Es geht hier nur darum, ob die unterschiedlichen Code-Varianten bei dem jeweiligen Compiler einen Performance-Unterschied machen
- Vergleichen Sie nur die Messergebnisse der Code-Varianten eines Compilers untereinander
- Interpretieren Sie nicht mehr in die Zahlen rein, als da drin steht
- Vergessen Sie nicht, dass es auch Mess-, Auswertungs-, Rechen- und Übertragungsfehler geben kann.
-
Ich schreibe extra keine absoluten Zeit-Messwerte in die Tabellen
- Lesen und Nutzen Sie also alles Folgende mit Vorsicht, Skepsis und Verstand
2. Praxis
2.1 Schleifen
-
Schleifen optimieren
- Schleifen haben einen sehr grossen Einfluss auf die Performance, da sie oft durchlaufen werden
- Daher besonders wichtig für Optimierungen
- Mögliche Optimierungen
2.1.1 Konstante Ausdrücke außerhalb der Schleife berechnen
- Machen moderne Compiler automatisch
-
Konstante Ausdrücke können auch Funktions-Aufrufe sein
- Dies kann der Compiler im Normallfall nicht erkennen
-
Ausnahmen:
- "inline" Funktionen
- Compiler, die quelltext-übergreifend optimieren
- C++11 Funktionen mit "constexpr" Schlüsselwort
// Variante 1 - Berechnung innerhalb der Schleife
int fct1(int n, int m)
{
int res = 0;
for (int i=0; i<65536; ++i)
{
res += n*m;
}
return res;
}
// Variante 2 - Berechnung ausserhalb der Schleife
int fct2(int n, int m)
{
int res = 0;
const int mul = n*m;
for (int i=0; i<65536; ++i)
{
res += mul;
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Innerhalb | 1,7 | 1,0 | 1,0 | 1,0 | 1,1 | 1,0 | 1,0 |
| Ausserhalb | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.1.2 Scope Variablen wiederverwenden
- Scope Variablen außerhalb des Schleifen-Rumpfs definieren und wieder verwenden
- Vermeidet aufwändige Konstruktion und Destruktion
- Vom Typ abhängig, d.h. ausprobieren und messen
-
Bei Basis-Datentypen bringt dies mit Sicherheit nichts
- Da sie keine aufwändige Konstruktion und Destruktion haben
// Variante 1 - immer neue Scope-Variable "s"
void f1(const vector<string>& v)
{
for (unsigned int i=0; i<v.size(); ++i)
{
string s(v[i]);
}
}
// Variante 2 - Variable "s" wiederverwenden
void f2(const vector<string>& v)
{
string s;
for (unsigned int i=0; i<v.size(); ++i)
{
s=v[i];
}
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Neu | 1,0 | 1,0 | 1,0 | 1,1 | 1,1 | 1,05 | 1,05 |
| Wiederverwendung | 1,0 | 1,0 | 1,35 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.1.3 Schleifen rückwärts statt vorwärts durchlaufen
-
Kann schneller sein, da viele Prozessoren bei Rechenoperationen immer automatisch mit auf "0" prüfen
- Extra Prüfungs-Operation fällt dann weg
- Nur sinnvoll bei Integer-Schleifen mit 0-Abbruch
-
Ist selbst dann nicht immer möglich
- Verkehrte Reihenfolge des Durchlaufs
- Aufpassen bei unsigned Typen mit der Abbruch-Bedingung
// Variante 1 - vorwaerts
int fct1(int n)
{
int res = 0;
for (int i=0; i<n; ++i)
{
res += i;
}
return res;
}
// Variante 2 - rueckwaerts
int fct2(int n)
{
int res = 0;
for (int i=n-1; i>=0; --i)
{
res += i;
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Vorwärts | 1,0 | 1,0 | 1,0 | 1,4 | 1,4 | 1,0 | 1,0 |
| Rückwärts | 1,0 | 1,3 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.1.4 Schleifen ausrollen
- In der Schleife nicht ein Element, sondern direkt Mehrere bearbeiten
- Reduziert den Schleifen-Overhead
- Extra-Aufwand für die Berücksichtigung der nicht in der Schleife abgearbeiteten Elemente
// Variante 1 - normale Schleife
int fct1(int n)
{
int res = 0;
for (int i=0; i<n; ++i)
{
res += i;
}
return res;
}
// Variante 2 - Schleife für 2 Werte
int fct2(int n)
{
int res = 0;
for (int i=0; i<n-1; i+=2)
{
res += i + i + 1;
}
if (n%2)
res += n-1;
return res;
}
// Variante 3 - Schleife für 3 Werte
int fct3(int n)
{
int res = 0
for (int i=0; i<n-2; i+=3)
{
res += i + i + 1 + i + 2;
}
int rest = n%3;
if (rest==1)
res += n - 1;
else if (rest==2)
res += n + n - 3;
return res;
}
// Variante 4 - Schleife für 10 Werte
// Achtung - Case-Bloecke absichtlich ohne "break"
int fct4(int n)
{
for (int i=0; i<n-9; i+=10)
{
res += 10*i + 45;
}
switch (n%10)
{
case 9:
res += n - 9;
case 8:
res += n - 8;
case 7:
res += n - 7;
case 6:
res += n - 6;
case 5:
res += n - 5;
case 4:
res += n - 4;
case 3:
res += n - 3;
case 2:
res += n - 2;
case 1:
res += n - 1;
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Schleife 1-fach | 7,3 | 5,2 | 8,8 | 9,0 | 9,1 | 5,2 | 5,7 |
| Schleife 2-fach | 4,2 | 4,3 | 4,5 | 4,2 | 4,3 | 4,3 | 3,5 |
| Schleife 3-fach | 3,8 | 2,8 | 3,0 | 2,8 | 2,9 | 2,9 | 2,6 |
| Schleife 10-fach | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.2 Sprünge
- Sprünge können den auszuführenden Code länger machen
- Sprünge arbeiten gegen den Prozessor (Pipeline, Caches,...)
- Darum Sprünge vermeiden, minimieren oder zumindest optimieren
- Mögliche Optimierungen
2.2.1 Fallunterscheidungen sortieren
- If/ElseIf-Kaskaden und Switch/Case-Vergleiche sind letztlich Abfragen, die der Rechner nacheinander ausführen muss, bis er einen Treffer landet
-
Steht die häufigst wahre Abfrage hinten, so müssen häufig viele unnütze Abfragen ausgeführt werden.
- Die Statements nach Wahrscheinlichkeit sortieren - wahrscheinlichste Abfrage nach vorne, usw.
- Es gibt Compiler (z.B. ICC), die mit instrumentalisiertem Code Wahrscheinlichkeits-Analysen machen, und dann in einem weiteren Compiler-Durchlauf den Code selber entsprechend umbauen.
- Dies ist eine der Sachen, die virtuelle Maschinen wie z.B. die JVM prinzipiell viel besser könn(t)en, da sie Laufzeit-Analysen direkt in den Just-In-Time compilierten Code einbauen können.
- Achtung - der Aufwand der Abfragen soltle mit berücksichtigt werden
-
- Sind Abfragen gleich wahrscheinlich, so sollten aufwändige Abfragen nach hinten gestellt werden
- Extrem aufwändige Abfragen, selbst wenn recht wahrscheinlich, sollten vielleicht mehr nach hinten
-
Sprung-Tabellen können noch schneller sein (siehe Kapitel 2.2.2)
- Manchmal können Compiler selber Sprung-Tabellen erstellen, und machen das dann auch
-
Hinweis: zu diesem Thema gibt es keinen extra Code und keine extra Messungen
- Im nächsten Kapitel 2.2.2 "Sprung-Tabellen nutzen") wird die Sortierung mit berücksichtigt
2.2.2 Sprung-Tabellen nutzen
-
Sind Case-Konstanten kleine Zahlen kann man:
- Case-Anweisung in Funktion auslagern
- Array mit Funktions-Zeigern und Case-Konstante als Index
- Machen manche Compiler automatisch
- Funktions-Objekte können schneller sein als Funktions-Zeiger
- Hat der Case-Konstanten Bereich zu viele zu große Lücken, kann eine Hash-Map (std::unsorted_map) oder eine Map (std::map) helfen
- Beruht die Abfrage nicht auf Integer-Typen, kann eine Hash-Map (std::unsorted_map) oder eine Map (std::map) helfen
-
Hinweise
- Bei den Messungen waren die Eingabe-Parameter nicht gleichverteilt, damit die Sortierung (siehe Kapitel 2.2.1) sich bemerkbar machen kann.
- Die Messungen existieren nur für den GCC 4.6 und die Microsoft Visual Studios 2010 und 11 Beta
- Das beim Microsoft Visual Studios 11 Beta die sortierten If/Else Abfragen schneller sind als das Array mit Funktions-Zeigern entspricht nicht meiner Erwartung - mehrfache Messungen zeigten bei mir aber immer dieses Ergebnis.
// Variante 1 - switch
int fct1(const vector<e>& v)
{
int res = 0;
for (int i=0; i<int(v.size()); ++i)
{
switch (v[i])
{
case e1:
res += f1();
break;
case e2:
res += f2();
break;
case e3:
res += f3();
break;
case e4:
res += f4();
break;
case e5:
res += f5();
break;
case e6:
res += f6();
break;
case e7:
res += f7();
break;
case e8:
res += f8();
break;
case e9:
res += f9();
break;
}
}
return res;
}
// Variante 2 - switch sortiert
int fct2(const vector<e>& v)
{
int res = 0;
for (int i=0; i<int(v.size()); ++i)
{
switch (v[i])
{
case e9:
res += f9();
break;
case e6:
res += f6();
break;
case e7:
res += f7();
break;
case e3:
res += f3();
break;
case e8:
res += f8();
break;
case e5:
res += f5();
break;
case e4:
res += f4();
break;
case e2:
res += f2();
break;
case e1:
res += f1();
break;
}
}
return res;
}
// Variante 3 - if/else
int fct3(const vector<e>& v)
{
int res = 0;
for (int i=0; i<int(v.size()); ++i)
{
if (v[i]==e1)
{
res += f1();
}
else if (v[i]==e2)
{
res += f2();
}
else if (v[i]==e3)
{
res += f3();
}
else if (v[i]==e4)
{
res += f4();
}
else if (v[i]==e5)
{
res += f5();
}
else if (v[i]==e6)
{
res += f6();
}
else if (v[i]==e7)
{
res += f7();
}
else if (v[i]==e8)
{
res += f8();
}
else if (v[i]==e9)
{
res += f9();
}
}
return res;
}
// Variante 4 - if/else sortiert
int fct4(const vector<e>& v)
{
int res = 0;
for (int i=0; i<int(v.size()); ++i)
{
if (v[i]==e9)
{
res += f9();
}
else if (v[i]==e6)
{
res += f6();
}
else if (v[i]==e7)
{
res += f7();
}
else if (v[i]==e3)
{
res += f3();
}
else if (v[i]==e8)
{
res += f8();
}
else if (v[i]==e5)
{
res += f5();
}
else if (v[i]==e4)
{
res += f4();
}
else if (v[i]==e2)
{
res += f2();
}
else if (v[i]==e1)
{
res += f1();
}
}
return res;
}
// Variante 5 - Array mit Funktions-Zeigern
int fct5(const vector<e>& v)
{
static array<int(*)(), 9> fcts = { f1, f2, f3, f4, f5, f6, f7, f8, f9 };
int res = 0;
for (int i=0; i<int(v.size()); ++i)
{
res += fcts[v[i]]();
}
return res;
}
// Variante 6 - Map mit Funktions-Zeigern
int fct6(const vector<e>& v)
{
static map<e, int(*)()> fcts;
if (fcts.empty())
{
fcts[e1] = f1;
fcts[e2] = f2;
fcts[e3] = f3;
fcts[e4] = f4;
fcts[e5] = f5;
fcts[e6] = f6;
fcts[e7] = f7;
fcts[e8] = f8;
fcts[e9] = f9;
}
int res = 0;
for (int i=0; i<int(v.size()); ++i)
{
res += fcts[v[i]]();
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| switch | --- | --- | 1,6 | --- | --- | 1,4 | 1,4 |
| switch sortiert | --- | --- | 1,4 | --- | --- | 1,5 | 1,1 |
| if/else | --- | --- | 1,9 | --- | --- | 3,2 | 2,7 |
| if/else sortiert | --- | --- | 1,2 | --- | --- | 1,3 | 1,0 |
| Array | --- | --- | 1,0 | --- | --- | 1,0 | 1,8 |
| Map | --- | --- | 3,3 | --- | --- | 4,5 | 6,6 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.2.3 Vererbung statt Fallunterscheidungen
-
Vererbung statt Fallunterscheidungen
- Ist letztlich das Ersetzen von Switch/Case-Abfragen mit einer Sprung-Tabelle
- Die VTBL ist hier die implizite Tabelle
- Code ist außerdem viel wartungsfreundlicher
-
Hinweis: zu diesem Thema gibt es keine Messungen
- Bei wenigen Typen ist die Switch-Lösung typischerweise schneller, aber viel unleserlicher und schlechter wartbar
- Hier würde ich nur im äußersten Performance-Notfall die schöne Vererbungs-Lösung der Performance opfern
// Variante 1 - switch ueber Typ-Enumeration
struct A
{
Type type;
};
void fct1(A& a)
{
switch (a.type)
{
case BType:
fb(a);
break;
case CType:
fc(a);
break;
}
}
// Variante 2 - Vererbung
struct A
{
virtual ~A() {}
virtual void f() = 0;
};
struct B : A
{
virtual void f() { fb(*this); }
}
struct C : A
{
virtual void f() { fc(*this); }
}
void doit(A& a)
{
a.f();
}
2.2.4 Sprünge minimieren
-
Sprünge minimieren
- Sprünge sind zusätzlicher Code
- Sprünge arbeiten gegen den Prozessor (Pipeline, Caches,...)
- Sprünge minimieren macht meist auch den einzelnen Code-Flow einfacher
-
Der Performance-Vorteil ist dann die Summe zweier Effekte
- Weniger Sprünge
- Gradliniegerer Code
-
Tipp um Sprünge zu erkennen und dann zu minimieren:
- Über den erzeugten Assembler-Code "nachdenken"
- Welcher Code erzeugt welche Sprünge?
// Variante 1 - Originalcode
int fct1()
{
int res = 0;
if (i%2) res += f1();
res += f2();
if (i%2) res += f3();
res += f4();
if (i%2) res += f5();
res += f6();
return res;
}
// Variante 2 - weniger Spruenge, aber Code-Verdopplung
int fct2()
{
int res = 0;
if (i%2)
{
res += f1();
res += f2();
res += f3();
res += f4();
res += f5();
res += f6();
}
else
{
res += f2();
res += f4();
res += f6();
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Original | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 | 1,6 | 1,5 |
| Optimiert | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.2.5 Sprünge vermeiden
- Anderer Algorithmus kann Sprünge minimieren oder vermeiden
-
Beispiel
- Wandlung einer Zahl von "0-15" in das Hexadezimal-Äquivalent-Zeichen "0-F"
- Lösung 1 mit If-Anweisung und Unterscheidung der Bereiche "0-9" und "10-15"
- Lösung 2 mit direktem Array-Zugriff
// Variante 1 - Wandlung mit If-Anweisung (Sprung)
char fct1(int v)
{
assert(v>=0);
assert(v<16);
if (v>9)
return 'A'+v-10;
return '0'+v;
}
// Variante 2 - Wandlung mit Array-Zugriff
char fct2(int v)
{
assert(v>=0);
assert(v<16);
return "0123456789ABCDEF"[v];
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| If-Anweisung | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 | 1,1 | 1,0 |
| Array-Zugriff | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3 Funktionen
- Der auszuführende Code beteht primär aus Funktionen und Funktions-Aufrufen
- Darum können Optimierungen dort viel bringen
-
Achtung - mit C++11 ändert sich das Bild
- R-Value Referenzen und Move-Konstruktoren können Kopien verhindern
- Sehen wir noch beim Thema Kopien und String-Addition - siehe Kapitel 2.4.2
- Mögliche Optimierungen
2.3.1 Korrekte Übergabe-Art
-
Optimale Übergabe-Art wählen
-
Call by Value (cbv)
- Objekte werden kopiert
-
Call by Const Reference (cbcr)
- Auf die Objekte wird eine Const-Referenz übergeben
-
Call by Value (cbv)
-
98% Regel
-
Basis-Datentypen (elementare Datentypen, Zeiger und Enums) per Kopie
- Smart-Pointer zählen hier nicht zu - sie sind Klassen, keine Zeiger
- Alles andere als Const-Referenz
-
Basis-Datentypen (elementare Datentypen, Zeiger und Enums) per Kopie
-
Mögliche Ausnahmen
-
Iteratoren typischerweise als Kopie
- Siehe z.B. STL Algorithmen
- Iteratoren sollten daher immer sehr klein sein
- Funktionen mit lokalen Kopien
- Multi-Threading
-
Iteratoren typischerweise als Kopie
-
In C++11 mit R-Value-Referenzen wird die Regel komplizierter
- Hier nicht berücksichtigt
- 3 Beipiele:
2.3.1.1 Vergleich Übergabe elementarer Datentypen per "cbv" und "cbcr"
- Integrale-Typen: "char", "short", "int" & "long"
- Fließkomma-Typen: "floag", "double" & "long double"
-
Ergebnis:
- Die 98% Regel greift - elementare Datentypen per "cbv"
- Aber Referenzen sind meist gleich schnell - gerade bei den neueren Compilern. Ich habe nicht überprüft, ob die neueren Compiler hier optimieren, oder andere Effekte dies verursachten.
- Achtung - der Ergebnisse lagen oft sehr dicht beieinander. Daher können im einzelfall auch Messungenauigkeiten und Schwankungen eine Rolle spielen.
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| char cbv | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| char cbcr | 1,2 | 1,0 | 1,1 | 1,1 | 1,0 | 1,0 | 1,0 |
| short cbv | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| short cbcr | 1,2 | 1,0 | 1,1 | 1,1 | 1,0 | 1,0 | 1,0 |
| int cbr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| int cbcr | 1,2 | 1,0 | 1,0 | 1,1 | 1,0 | 1,0 | 1,0 |
| long cbv | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| long cbcr | 1,2 | 1,0 | 1,0 | 1,1 | 1,0 | 1,0 | 1,0 |
| float cbv | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| float cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| double cbv | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| double cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,05 | 1,0 |
| long double cbv | 1,2 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| long double cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,05 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3.1.2 Vergleich Übergabe von Klassen per "cbv" und "cbcr"
- Alle Klassen waren PODs, d.h. keine virtuellen Funktionen oder andere Dinge, die das Speicherlayout und die Kopier-Semantik beeinflussen können.
- Die Klassen bestanden einfach nur aus ein, zwei, drei oder vier "int's"
-
Ergebnis:
- Die 98% Regel greift - selbst die kleinste Klasse per "cbcr"
- Beim Microsoft Visual Studio 11 Beta waren Kopien gleich schnell. Ich habe nicht überprüft, ob der Compiler hier optimiert, oder andere Effekte dies verursachten.
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| 1 x int - cbv | 1,4 | 1,2 | 1,2 | 1,2 | 1,1 | 1,8 | 1,0 |
| 2 x int - cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| 2 x int - cbv | 1,6 | 1,3 | 1,4 | 1,5 | 1,5 | 2,0 | 1,0 |
| 2 x int - cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| 3 x int - cbv | 1,8 | 1,7 | 2,2 | 2,3 | 2,1 | 2,1 | 1,0 |
| 3 x int - cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| 4 x int - cbv | 2,2 | 1,7 | 2,5 | 2,8 | 2,2 | 2,2 | 1,0 |
| 4 x int - cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3.1.3 Vergleich Übergabe eines Shared-Pointers per "cbv" und "cbcr"
- Ein Shared-Pointer ist (wie alle Smart-Pointer) eine Klasse => Übergabe per Const-Referenz ("cbcr")
- Viele Programmierer ordnen ihn aber als Zeiger ein, und nehmen daher Übergabe per Kopie ("cbv")
- Der Test soll zeigen, was richtig ist
-
Ergebnis ist klar: Übergabe per Referenz ist viel schneller
- Ein Smart-Pointer ist eine Klasse, die sich wie ein Zeiger verhält.
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Shared-Ptr cbv | 2,1 | 10,2 | 7,8 | 16,0 | 39,0 | 8,1 | 8,1 |
| Shared-Ptr cbcr | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3.2 Parallele Funktionen implementieren
-
Bei vielen Funktions-Aufrufen entstehen temporäre Objekte, da es die genau passende Funktion nicht gibt
- Temporäre Objekte kosten Performance und Speicher
- Lösung: passende Funktion(en) parallel implementieren
-
Beispiel:
-
Interface mit nur einer Funktion
- void fct(const string&)
-
Aufruf mit einer Zeichenketten-Konstante oder einem "const char*"
- => Erzeugung eines temporären String-Objekts
-
Statt dessen zwei Funktionen anbieten
- void fct(const string&)
- void fct(const char*)
- Hinweis: die Klasse "std::string" hat mehrere entsprechend überladene "==" Operatoren. Sonst hätten wir das Problem im Beispiel-Code ja nur verschoben...
-
Interface mit nur einer Funktion
// Variante 1 - nur String-Funktion
struct A
{
bool name_match(const string& s) const
{
return name_==s;
}
string name_;
};
// Variante 2 - parallele Funktion
struct B
{
bool name_match(const string& s) const
{
return name_==s;
}
bool name_match(const char* p) const
{
return name_==p;
}
string name_;
};
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Nur String | 8,4 | 5,2 | 6,4 | 2,1 | 4,5 | 3,5 | 4,5 |
| Parallele Fkt | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3.3 Return Wert Optimierung
- Problem, wenn große Objekte per Kopie zurückgegeben werden
-
Compiler darf hier die Kopie wegoptimieren
- Achtung - nicht selbstverständlich
-
RVO beschreibt eigentlich nur:
- Konstruktion eines neuen Objekts mit Fkt-Aufruf zur Initialisierung
- Objekt muss in der Funktion in der return Anweisung erzeugt werden
-
Technik ist schon im "Annotated C++ Reference Manual" ("ARM", von 1989) beschrieben
- Siehe Kapitel 5, Literatur
-
Moderne Compiler können noch mehr optimieren
- Früher nur bei Rückgabe unbenannter Objekte
- Früher nur bei Konstruktion an Aufrufstelle
- Hinweis - bei den Messungen waren die Aufruf-Stellen gleichwertig. Im Code soll nur klar werden, dass Variante 2 schon nicht mehr die RVO-Normallform ist, da der Funktions-Aufruf nicht in einer Objekt-Konstruktion statt findet (vergleiche Variante 1).
// Variante 1 - RVO Normallform
A fct1(int n1, int n2, int n3, int n4)
{
return A(n1, n2, n3, n4);
}
int main()
{
A a(fct1(1, 2, 3, 4));
}
// Variante 2 - RVO in Anweisung
A fct2(int n1, int n2, int n3, int n4)
{
return A(n1, n2, n3, n4);
}
int main()
{
A a;
a += fct2(1, 2, 3, 4);
}
// Variante 3 - RVO benanntes Objekt
A fct3(int n1, int n2, int n3, int n4)
{
A a(n1, n2, n3, n4);
return a;
}
int main()
{
A a(fct3(1, 2, 3, 4));
}
// Variante 4 - RVO, Setter
A fct4(int n1, int n2, int n3, int n4)
{
A a;
a.set(n1, n2, n3, n4);
return a;
}
int main()
{
A a(fct4(1, 2, 3, 4));
}
// Variante 5 - Referenz-Parameter
void fct5(A& a, int n1, int n2, int n3, int n4)
{
a.set(n1, n2, n3, n4);
}
int main()
{
A a;
fct5(a, 1, 2, 3, 4);
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| RVO Normalform | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| RVO in Anweisung | 1,2 | 1,0 | 1,0 | 1,4 | 1,4 | 1,2 | 1,0 |
| Benanntes Objekt | 1,3 | 1,0 | 1,0 | 1,2 | 1,0 | 1,0 | 1,0 |
| Obj. mit Setter | 1,3 | 1,0 | 1,0 | 1,2 | 1,0 | 1,0 | 1,0 |
| Referenz-Parameter | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3.4 Alternative Rückgabe-Optimierung
- Alternative zu RVO
- Statt Kopie zurückzugeben, Referenz auf funktions-statisches Objekt
-
Probleme:
-
Multi-Threading
- Thread-Local Variablen könnten eine Lösung sein
-
Probleme bei Rückgaben, die sich verändern
- Denn es exisitiert vielleicht eine Referenz darauf
-
Multi-Threading
- Eher eine Lösung für Spezialfälle. Im Normallfall sollte RVO greifen - und ist problemloser. Aber messen, ob RVO auch wirklich greift.
// Variante 1 - Kopie-Rueckgabe
string name_as_copy() const
{
return "Mein toller Name";
}
// Variante 2 - Referenz-Rueckgabe
const string& name_as_reference() const
{
static string s("Mein toller Name");
return s;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Kopie | 50,0 | 29,1 | 38,6 | 42,1 | 33,3 | 21,6 | 61,5 |
| Referenz | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.3.5 Funktions-Objekte statt Funktionen
- Bevorzuge Funktions-Objekte vor Funktionen
-
Compiler können Funktions-Objekte besser optimieren
- Funktions-Zeiger sind eine Optimierungs-Barriere
- Typen enthalten alle Informationen und sind "laufzeitfrei"
- Lambda-Bibliotheken wie die Boost-Lambda-Library (BLL) oder Boost.Phoenix erzeuge auch Funktions-Objekte
- In C++11 sind Lambda-Ausdrücke empfehlenswert, da sie auch Funktions-Objekte sind
// Variante 1 - Funktion
bool my_lt(int arg1, int arg2)
{
return arg1<arg2;
}
vector<int> v = { ... };
sort(v.begin(), v.end(), my_lt);
// Variante 2 - Funktions-Objekt
struct MyLt
{
bool operator()(int arg1, int arg2) const
{
return arg1<arg2;
}
};
vector<int> v = { ... };
sort(v.begin(), v.end(), MyLt());
// Variante 3 - Funktions-Objekt mit Boost-Lambda-Library (BLL)
#include <boost/lambda/lambda.hpp>
using namespace boost::lambda;
vector<int> v = { ... };
sort(v.begin(), v.end(), _1<_2);
// Variante 4 - C++11 Lambda-Ausdruck
vector<int> v = { ... };
sort(v.begin(), v.end(), [](int arg1, int arg2) { return arg1<arg2; });
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Funktion | 3,2 | 2,6 | 2,6 | 2,2 | 2,2 | 2,3 | 2,3 |
| Fkt-Objekt | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| BLL | 4,9 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| C++11 Lambda | --- | --- | --- | --- | --- | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.4 Kopien
- Kopien und temporäre Objekte vermeiden
- Typisches C++ (Performance) Problem
- Vielleicht DAS C++ Performance Problem
- Man muss wissen bzw. erkennen, wo überall Kopien bzw. temporäre Objekte angelegt werden
-
Geht oft Hand-in-Hand mit Funktions-Parametern oder -Rückgaben
- Vergleiche "Parallele Funktionen implementieren" - Kapitel 2.3.2
- Auch dort ging es um die Vermeidung temporärer Objekte
-
Achtung - mit C++11 ändert sich das Bild
- R-Value Referenzen und Move-Konstruktoren können Kopien verhindern
- Sehen wir noch beim Thema Addition - siehe Kapitel 2.4.2
- Mögliche Optimierungen
2.4.1 Schleifen-Elemente als Referenz auslegen
- Schleifen-Elemente als Const-Referenz auslegen
- Nur Basis-Datentypen per Kopie
- Vergleichbar zu Funktions-Übergaben
-
Gilt auch für C++11 Schleifen mit "auto"
- "auto&" bzw. "const auto&" nehmen
// Variante 1 - Kopie
string::size_type fct1(const vector<string>& v)
{
string::size_type res = 0;
vector<string>::const_iterator it = v.begin();
vector<string>::const_iterator eit = v.end();
for (; it!=eit; ++it)
{
string s = *it;
res += s.length();
}
return res;
}
// Variante 2 - Const-Referenz
string::size_type fct1(const vector<string>& v)
{
string::size_type res = 0;
vector<string>::const_iterator it = v.begin();
vector<string>::const_iterator eit = v.end();
for (; it!=eit; ++it)
{
const string& s = *it;
res += s.length();
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Kopie | 80,0 | 62,0 | 12,3 | 47,0 | 15,0 | 21,0 | 20,7 |
| Const-Referenz | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.4.2 Temporäre Objekte bei der Addition verhindern
- Ein Problem bei der Addition mit dem Operator + ist, dass temporäre Objekte entstehen
-
Beispielhaft wollen wir uns das bei der String-Addition anschauen
- Diese hält auch noch ein paar andere Erkenntnisse für uns bereit
-
Wie verhindert man Kopien bei z.B. der Addition:
- += Operator kann Kopien verhindern
-
Typische Anwendung von Expression Templates
- Aber die können noch mehr, aber eben auch das
-
In C++11 mit R-Value Referenzen kein Problem mehr
- Wie man auch in den Messungen sieht
- Siehe gelb unterlegte Felder
- Hier ist der + Operator schneller als der += Operator (ohne "reserve")
-
String-Addition kann man noch mehr beschleunigen
- Indem man vorher die notwendige Größe reserviert
- Das ist dann auch noch besser als der + Operator mit R-Value Referenzen
- Achtung - die Addition steht hier nur stellvertretend für viele Operatoren und Funktionen, bei denen temporäre Objekte entstehen. Spezielle Funktionen und/oder C++11 R-Value Referenzen sollten dann die Lösung sein. Leider wird der Quelltext dann meist unleserlicher, wie man auch in den Beispielen sieht. Variante 1 ist am Schönsten, aber auch am Langsamsten. Variante 3 am Schnellsten, aber auch am Unleserlichsten.
// Variante 1 - Operator +
string fct1(const string& s1, const string& s2, const string& s3, const string& s4)
{
return s1 + s2 + s3 + s4;
}
// Variante 2 - Operator +=
string fct2(const string& s1, const string& s2, const string& s3, const string& s4)
{
string s = s1;
s += s2;
s += s3;
s += s4;
return s;
}
// Variante 3 - Operator += und reserve
string fct2(const string& s1, const string& s2, const string& s3, const string& s4)
{
string::size_type len = s1.length() + s2.length() + s3.length() + s4.length();
string s;
string s.reserve(len);
s += s1;
s += s2;
s += s3;
s += s4;
return s;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Operator + | 1,9 | 3,1 | 3,1 | 5,6 | 7,2 | 2,4 | 2,5 |
| Operator += | 1,0 | 2,2 | 2,2 | 2,6 | 3,3 | 2,6 | 2,6 |
| += & reserve | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.4.3 Nutze "swap" statt einer Zuweisung
- Nutze "swap" statt einer Zuweisung - wenn möglich
- Source-Objekt ist danach kaputt
- Dafür keine Kopie nötig, sondern nur einfaches scnelles "swap"
- Ist daher nicht immer möglich
-
Wenn möglich, kann es im Einzelfall sehr viel bringen
- Stark abhängig von den Konstruktions- und Destruktions-Kosten
// Variante 1 - Zuweisung
void fct1(string& s)
{
string res("abcdefghijklmnopqrstuvwxyz");
res += "12345678901234567890123456789012345678901234567890";
s = res;
}
// Variante 2 - swap
void fct1(string& s)
{
string res("abcdefghijklmnopqrstuvwxyz");
res += "12345678901234567890123456789012345678901234567890";
s.swap(res);
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Zuweisung | 1,4 | 1,5 | 1,3 | 1,1 | 1,2 | 2,1 | 2,1 |
| swap | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.5 Speicher-Management
- Lokalen Speicher bevorzugen
- Nutzung dynamischen Speichers minimieren
-
Denn:
- Dynamischer Speicher ist teuer
- Stack-Speicher ist billig
- "alloca" kann eine Hilfe sein
- Achtung - die Stack-Größe ist begrenzt (1 MByte ist Default bei Windows, 8 MByte bei Linux)
-
Dynamischen Speicher optimieren
-
"new/delete" global überladen und Heaps verschiedener Größe machen
- Weniger MT Synchronisierung
-
"new/delete" klassen-spezifisch überladen
- Weniger Fragmentierung
- Weniger MT Synchronisierung
-
"new/delete" global überladen und Heaps verschiedener Größe machen
- Daten packen kann in Einzelfällen die Nutzung des dynamischen Speichers entlasten
- Mögliche Optimierungen
2.5.1 Lokalen Speicher (Stack) bevorzugen
- Lokalen Speicher (Stack) gegenüber dynamischem Speicher (Heap) bevorzugen
// Variante 1 - lokale Variable
void fct1()
{
char a[100];
}
// Variante 2 - alloca
void fct2()
{
char* p = (char*)alloca(100);
}
// Variante 3 - Heap
void fct3()
{
char* p = new char[100];
delete [] p;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Lokale Var. | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| Alloca | 1,4 | 1,3 | 1,3 | 1,25 | 1,25 | 3,5 | 3,5 |
| Heap - new | 45,0 | 32,0 | 26,6 | 43,0 | 43,0 | 37,3 | 35,5 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.5.2 Nutze "reserve" bei möglichen Typen
- Nutze reserve bei geblockten container-artigen Typen
- Dynamische Container, die ihren Speicher als Block verwalten, müssen ihn beim Wachsen reallokieren => aufwändig
-
Ist vorher bekannt, wie viele Objekte in den Container kommen, kann vorher entsprechend Speicher reserviert werden
- Typische Element-Funktion in der STL: "reserve"
- Dies verhindert teure Reallokation - minimiert die Nutzung der dynamischen Speicherverwaltung
- Beispiele: vector oder string (Kapitel 2.4.2)
2.6 Lokalität
-
Alle Programme laufen auf Hardware
- Hardware-Architektur beeinflusst Performance der Programm-Ausführung
-
Caches
- Bandbreite
- Wartezeiten (Latenz)
-
Die Latenz läßt sich "beeinflussen"
- Sie läßt sich natürlich nicht beeinflussen, aber wie oft sie zuschlägt
- Natürlich alles sehr hardware-abhängig
-
Wartezeiten entstehen, wenn ein schnelles Medium auf ein Langsameres wartet,
und das Nachladen eine gewisse Zeit dauert -
Auf dem folgenden Bild, das die typische Cache-Struktur aktueller Rechner beschreibt, sieht man
dass die Latenz-Zeiten und die Cache-Line Größen eine große Rolle für die Performance spielen (können).
- First Level Cache, ~64 Byte Cache-Line Größe, ~2..3 Takt-Zyklen Latenz zum Nachladen
- Second Level Cache, ~64 Byte Cache-Line Größe, ~12..20 Takt-Zyklen Latenz zum Nachladen
- Hauptspeicher, ~4 KByte Page Größe, ~200 Takt-Zyklen Latenz zum Nachladen
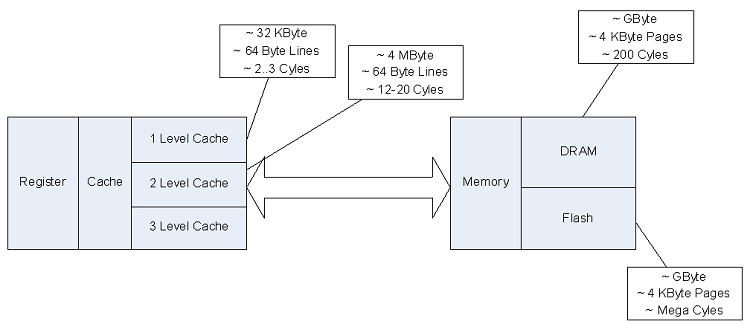
-
Lokalität von Daten fördern
- Damit passen sie in den Cache
- Weniger Cache-Mismatches, weniger Nachladen, weniger Latenz-Probleme
-
Aufpassen bei MT und Mehr-Prozessor-Maschinen
- Cache Synchronisationen können stören
- Stichwort: "Cache-Line Ping Pong"
- Mögliche Optimierungen
2.6.1 Daten linear durchlaufen
-
Versuchen Sie Daten immer linear (aus Speichersicht) zu durchlaufen
-
Beispiel:
- Zwei-dimensionales Array
- array<array<int, 8192>, 1024>
- Ein lesender Zugriff auf jedes Element
-
Zwei Arten des Durchlaufs:
- Aussen: äußeres Array, Innen: inneres Array
- Aussen: inneres Array, Innen: äußeres Array
- Siehe auch folgende Grafik
-
Beispiel:
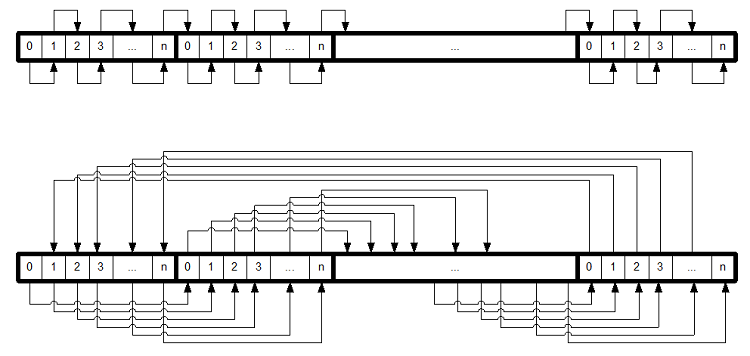
-
Aus der abstrakten Sicht des Programmierers ist beides identisch
- Aber einmal wird der Speicher linear durchlaufen
- Das andere Mal sprunghaft - und dabei leider ständig ein Cache-Nachladen erzwungen
- Hinweis - die unterschiedlichen Zeiten zwischen linearem und sprunghaftem Durchlauf zwischen den Compilern liegen hier wahrscheinlich primär nicht an den Compilern, sondern an der unterschiedlichen Hardware, auf denen die Tests gelaufen sind.
// Variante 1 - linearer Speicher-Durchlauf
int fct1(const array<array<int, 8192>, 1024>& a)
{
int res = 0;
const size_t ei = a.size();
const size_t ej = a[0].size();
for (size_t i=0; i<ei; ++i)
{
for (size_t j=0; j<ej; ++j)
{
res += a[i][j];
}
}
return res;
}
// Variante 2 - sprunghafter Speicher-Durchlauf
int fct2(const array<array<int, 8192>, 1024>& a)
{
int res = 0;
const size_t ei = a[0].size();
const size_t ej = a.size();
for (size_t i=0; i<ei; ++i)
{
for (size_t j=0; j<ej; ++j)
{
res += a[j][i];
}
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Linear | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| Sprunghaft | 22,2 | 22,1 | 23,9 | 26,0 | 25,5 | 19,6 | 19,7 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.6.2 Daten lokal packen
- Daten lokal packen
-
Klassen mit 4096 int-Zeigern
- const int size = 4096
-
Klasse A
- Zeiger und int Werte direkt in der Klasse
- D.h. die Daten liegen sehr lokal
-
Klasse B
- Zeiger in der Klasse
- Werte irgendwo im Heap
- Daten liegen daher wahrscheinlich verteilter
- Zugriff auf die Int-Werte nur über die Zeiger
// Variante 1 - Daten lokal gepackt
const int size = 8192;
struct A
{
A();
int a[size];
int* p[size];
};
A::A()
{
for (int i=0; i<size; ++i)
{
a[i] = i;
p[i] = &a[i];
}
}
int fct1(const A& a)
{
int res = 0;
for (int i=0; i<size; ++i)
{
res += *a.p[i];
}
return res;
}
// Variante 2 - Daten verstreut
const int size = 8192;
struct B
{
B();
~B();
int* p[size];
};
B::B()
{
for (int i=0; i<size; ++i)
p[i] = new int(i);
}
B::~B()
{
for (int i=0; i<size; ++i)
delete p[i];
}
int fct2(const B& b)
{
int res = 0;
for (int i=0; i<size; ++i)
{
res += *b.p[i];
}
return res;
}
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Lokal | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| Gestreut | 6,8 | 8,2 | 13,3 | 5,9 | 6,1 | 7,2 | 7,8 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.6.3 Bandbreite durch Packen optimieren
- Bandbreite durch Packen optimieren
-
Datenstrukturen so packen, dass es kein "Padding" gibt
- Padding - ungenutzter Speicher innerhalb eines Objekts, aufgrund von Verschnitt
-
Häufig werden Daten vom Compiler so im Speicher ausgerichtet, dass ihre Adresse durch 2/4/8/... teilbar ist,
da die Hardware dann schneller bzw. überhaupt zugreifen kann
-
Daten dann absteigend entsprechend ihrer Größe anordnen, um möglichst geringes Padding zu erzeugen
- Vergleiche folgende Grafik
-
Annahmen für die Grafik:
- char == 1 Byte, wird beliebig ausgerichtet
- short == 2 Byte, wird auf durch 2 teilbare Adresse ausgerichtet
- int == 4 Byte, wird auf durch 4 teilbare Adresse ausgerichtet
- Zeiger == 8 Byte, wird auf durch 8 teilbare Adresse ausgerichtet
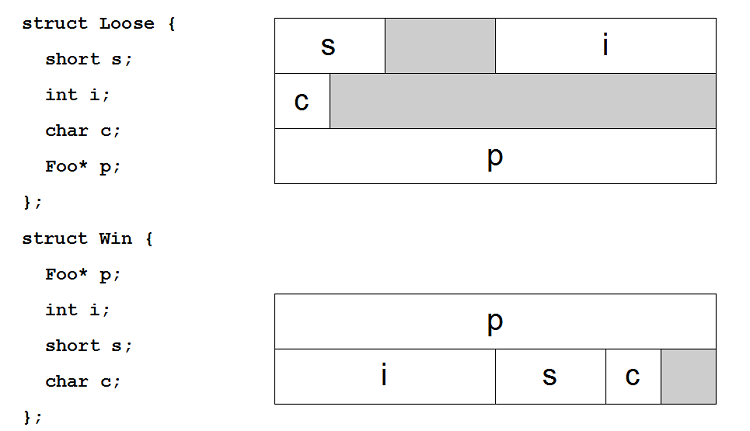
- Absteigend ausrichten anhand der Größe der Elemente erzeugt möglichst kompakte Daten-Strukturen
- => es passen mehr Daten in den Cache, in eine Cache-Line, in eine Speicher-Seite,...
- => selteneres Nachladen notwendig, weniger Latenz, mehr Performance...
- Hinweis: zu diesem Thema gibt es keinen Code
- Hinweis: der mögliche Performance-Gewinn ist sehr Code- und vorallem Hardware-Abhängig
| GCC 2.95 | GCC 4.1 | GCC 4.6 | MS 2003 | MS 2005 | MS 2010 | MS 11Beta | |
| Gepackt | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| Ungepackt | 1,2 | 1,2 | 1,2 | 1,2 | 1,2 | 1,2 | 1,2 |
Achtung - bei der Interpretation der Messergebnisse vergessen Sie bitte nicht die Hinweise aus Kapitel 1.2.
2.7 Lokalität & Algorithmen
- Versuche im Cache zu arbeiten
- Wähle die Algorithmen so aus, bzw. modifiziere sie so, dass sie möglichst selten einen Cache-Mismatch produzieren
-
Daten weniger bewegen (zwischen Cache und Speicher)
- Explizit schwierig, da es in C++ keine Befehle dafür gibt
- Aber in Assembler möglich
- Daten packen
- Daten-Strukturen verändern
- Verbesserungen bei den Datenbewegungen ist auch gut für Single-Core
-
"Cache oblivious Blocking"
- Problem solange rekursiv in Teil-Probleme zerlegen, bis die Daten in den Cache passen
-
Manchmal reicht
- Schleifen tauschen
- Schleifen block-mäßig durchlaufen
-
Beispiel - Sieb des Eratosthenes
-
Typische Implementierung mit zwei Schleifen
- Äussere Schleife findet die Primzahlen
- Die innere Schleife streicht die zusammengesetzten Zahlen
-
Aber: sehr cache-unfreundlich
- Da immer wieder über das gesamte Array gelaufen wird
- Und das Array ist meist viel größer als der Cache
-
Typische Implementierung mit zwei Schleifen
-
Besser: statt Array für alle Zahlen auf einmal abzuarbeiten:
- "Fenster" ins Array bilden (auf Cache-Größe normieren)
- Innere Schleife bei Ende des Fensters stoppen
- Dann äußere Schleife weiterlaufen lassen Dann innere Schleife für das nächste Fenster
- usw..
-
Algorithmus ist etwas komplizierter
- ~30 Zeilen statt ~20 Zeilen
-
Aber schneller - siehe schematische Grafik
- Abgeleitet aus echten Messungen
- Grüne Linie ist die Performance bei einem cache-freundlichen Algorithmus
- Rote Linie ist die Performance bei dem Standard-Algorithmus (cache-unfreundlich)
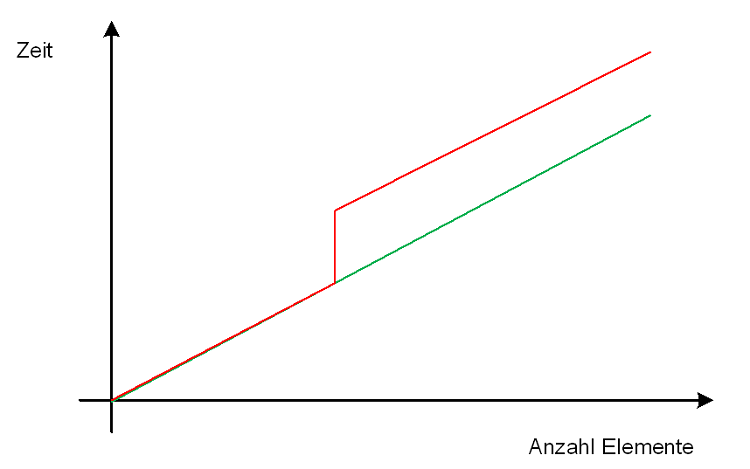
-
Noch schwieriger, aber sinnvoll für Mehrkern-Prozessoren
- Cache-freundlicher paralleler nicht-blockierender Algorithmus
- Im Internet findet man Beispiele mit "Open MP" mit ~60 Zeilen hierfür
3. Fazit
-
Viele Themen haben wir gar nicht oder zu kurz besprochen
- Kleinkram wie z.B. die Bevorzugung von Prä-Increment und -Decrement vor Post-Increment und -Decrement Operatoren
- C++ Sprachmittel (inline, const, constexpr, final, ...)
- Container, Algorithmen
- Architektur, Design & Idioms
- Multi-Threading
- Assembler
-
Und auch zu den Besprochenen gibt es noch viele Facetten
- Fassen Sie die Beispiele als Anregungen auf
- Probieren Sie aus
- Messen, messen, messen
- Performance ist ein weites und kompliziertes Thema
-
Performance (Tricks) ist (sind) sehr abhängig von
- Hardware
- Compiler
- Bibliotheks-Implementierungen
-
Von daher
- Ausprobieren
- Messen, messen, messen...
-
Aber nur Optimieren, wenn es sinnvoll ist
- Korrektheit, Lesbarkeit, Wartbarkeit geht vor
-
Viele Performance-Themen sind hardware abhängig
- Man sollte das C++ Speichermodell kennen und nutzen
-
Kompakte Container können durch Cache-Verhalten besser sein
- z.B. Vektor vs. Liste
-
Kompakt codierte Datenstrukturen können schneller sein
-
Bool Wert in einem Bit statt in Integer unterbringen
- Bool Wert muss bit-codiert werden
- Daten sind aber viel kompakter
-
Bool Wert in einem Bit statt in Integer unterbringen
- Gerade im Multi-Threading Fall muss man noch mehr aufpassen
- Also messen, messen, messen
-
Wichtig
- Gutes Design
- Gute Datenstrukturen
- Gute Algorithmen
- Die richtigen Bibliotheksmittel nutzen
-
Elementare "Fehler" auf Sprachebene vermeiden, z.B.:
- Zuviele Kopien
- Zuviele temporäre Objekte
- Dynamische statt statischer Speicherverwaltung
- Nutzung von Multi-Threading
- Also messen, messen, messen
- "There is no silver bullet for good performance"
- "Don't do it"
- "Don't do it now"
- Messen, messen, messen...
- Und - habe ich es schon gesagt? - vergessen Sie nicht zu messen, messen, messen,...
4. Profiler
Zum Messen der Performance nimmt am Besten einen Profiler - das sind Tools, die speziell für diesen Anwendungsfall erstellt sind. Hier eine alphabetische Liste der mir bekannten C++ Profiler und Profiling-Bibliotheken - Stand: 18.04.2012.-
Acumem - SlowSpotter
- Acumem wurde 2010 von RogueWave aufgekauft
- SlowSpotter wurde in das Produkt RogueWave ThreadSpotter integriert
- http://en.wikipedia.org/wiki/Acumem_SlowSpotter
- AMD - CodeAnalyst
-
Compuware - DevPartner Studio
- DevPartner Studio wurde von Micro Focus übernommen
- ElectricFence
- GCC Tool - gprof
- GlowCode
- Google Performance Tools (PerfTools)
- IBM Rational - Purify Plus (Quantify)
-
Intel - Parallel Studio
- http://software.intel.com/en-us/articles/intel-parallel-studio-home
- http://en.wikipedia.org/wiki/Parallel_Studio
- Enthält auch Intel VTune, siehe unten
-
Intel - VTune
- http://software.intel.com/en-us/articles/intel-vtune-amplifier-xe/
- http://en.wikipedia.org/wiki/VTune
- In Intel Parallel Studio enthalten, siehe oben
- Lightweight Technologies - LtProf
- Low Fat Profiler
- Luke Stackwalker
-
Micro Focus - DevPartner Studio
- http://www.microfocus.com/products/micro-focus-developer/devpartner/index.aspx
- http://en.wikipedia.org/wiki/DevPartner
- Ehemals Compuware, davor Nu-Mega
- Microsoft - Visual Studio Team System Profiler & Application Verifier
- Microsoft - Windows Performance Analysis Toolkit (WPT)
-
Nu-Mega - DevPartner Studio
- DevPartner Studio wurde von erst von Compuware, dann von Micro Focus übernommen
- Oprofile
- Oracle - Sun DTrace
- Oracle - Sun Studio Profiler
- Parasoft - Insure++
-
RogueWave - ThreadSpotter
- http://www.roguewave.com/products/threadspotter.aspx
- Acumem wurde von RogueWave übernommen, und der Acumem SlowSpotter ist im ThreadSpotter aufgegangen
- Shiny C++ Profiler
- Sleepy bzw. auch VerySleepy genannt
- SmartBear - AQtime
- Software Verify - Performance Validator
- STLSoft
- The Wall Soft - CodeTune
- Valgrind und KDE Visualisierungs-Tool "kcachegrind"
5. Literatur
-
Schon in diesem ewig alten und heute auch stark veraltetem Referenz-Werk zu C++
wird die Return-Wert-Optimierung (RVO) beschrieben:
- Margaret Ellis & Bjarne Stroustrup
- Annotated C++ Reference Manual
- ARM
- Sprache: Englisch
- Verlag: Addison-Wesley Longman
- ISBN: 978-0201514599
- Erscheinungs-Jahr: 1989
-
Überblick über viele Themen in C++, die mit Performance zu tun haben:
- Dov Bulka
- Efficient C++
- Performance Programming Techniques
- Sprache: Englisch
- Verlag: Addison-Wesley Longman
- ISBN: 978-0201379501
- Erscheinungs-Jahr: November 1999
-
Ein Buch zum Thema C++ Performance, das u.a. auch das Thema Speicher-Management bespricht.
Leider in vielen Belangen veraltet, aber trotzdem lesenswert:- Dietmar Deimling
- C++ Tuning
- Sprache: Deutsch
- Verlag: Heinz Heise
- ISBN: 978-3-88229-054-4
- Erscheinungs-Jahr: Mai 1995
-
Ein weiterer sehr empfehlenswerter Klassiker von Scott Meyers über die STL,
der u.a. auch Performance-Themen enthält:- Scott Meyers
- Effective STL
- 50 Specific Ways to Improve Your Use of the Standard Template Library
- Sprache: Englisch
- Verlag: Addison Wesley
- ISBN: 978-0201749625
- Erscheinungs-Jahr: Juli 2008 (11. Auflage)
-
Eigentlich geht der Titel am Inhalt vorbei. Das Buch handelt primär nicht von C++, sondern es geht mehr um Algorithmen und Daten-Strukturen,
wie z.B. Sortierung, Hashing oder Daten-Kompression. Der Code ist zwar in C++, aber mit modernem C++ Code hat er nicht viel
zu tun. Trotzdem - wenn die Themen für Sie interessant sind - dann kann sich dieses Buch für Sie lohnen:
- Steve Heller
- Optimizing C++
- Sprache: Englisch
- Verlag: Prentice Hall PTR
- ISBN: 978-0139774300
- Erscheinungs-Jahr: August 1999
-
Der Vorgänger vom obigen Buch "Optimizing C++" vom gleichen Autor (siehe oben) -
also höchstens für Sammler interessant. Wenn Sie die Themen des Buches interessieren, dann
besorgen Sie sich besser den Nachfolger "Optimizing C++" - dieses ist doch recht veraltet:
- Steve Heller
- Efficient C/C++ Programming
- Smaller, Faster, Better
- Sprache: Englisch
- Verlag: Academic Press Inc
- ISBN: 978-0123390950
- Erscheinungs-Jahr: Oktober 1994
-
Weniger ein C++ Buch - handelt es doch viel mehr von C und Assembler. Es ist eine sehr hardware-nahe
Lektüre und behandelt prozessor-spezifische Optimierungen unter Ausnutzung der jeweiligen
Prozessor-Architekturen. Da das Buch von 1997 ist, sind die Prozessoren und damit ein Groß-Teil der
Optimierungen leider nicht mehr aktuell - aber trotzdem eine faszinierende spannende Lektüre, sehr
empfehlenswert:
- Rick Booth
- Inner Loops
- A Sourcebook for Fast 32-bit Software Development
- Sprache: Englisch
- Verlag: Addison-Wesley Longman
- ISBN: 978-0201479607
- Erscheinungs-Jahr: Januar 1997
6. Links
- Wikibook: "Optimizing C++"
- Agner's Software optimization resources
- Bit Twiddling Hacks, by Sean Eron Anderson
- C++ Optimization Strategies and Techniques, by Pete Isensee
- Speicherverwaltung von Programmen optimieren, von Michael Riepe
- Wikipedia: "Return value optimization"
- Wikipedia: "Duff's device"
- CodePlanet Artikel über Profiler:
- Wikipedia: "Profiling"
- Wikipedia: "Profiler"
7. Versions-Historie
Die Versions-Historie dieses Artikels:-
Version 1
- 18.04.2012
- Initiale Version